 Image credit: Original Paper
Image credit: Original PaperAbstract
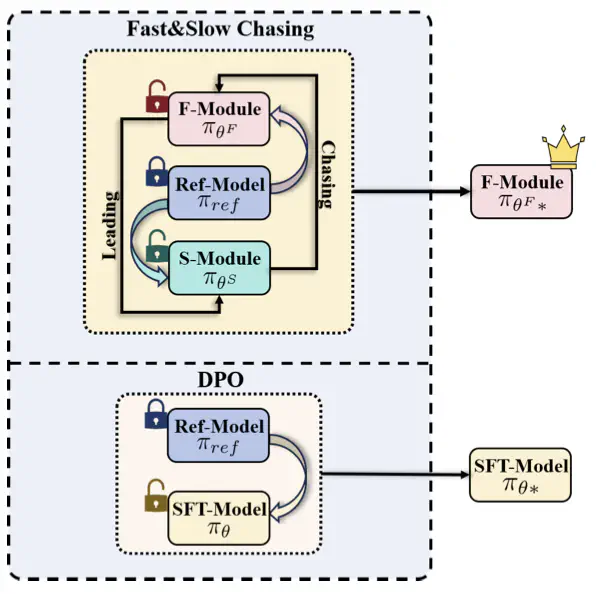
Direct Preference Optimization (DPO) improves the alignment of large language models (LLMs) with human values by training directly on human preference datasets, eliminating the need for reward models. However, due to the presence of cross-domain human preferences, direct continual training can lead to catastrophic forgetting, limiting DPO’s performance and efficiency. Inspired by intraspecific competition driving species evolution, we propose a Online Fast-Slow chasing DPO (OFS-DPO) for preference alignment, simulating competition through fast and slow chasing among models to facilitate rapid adaptation. Specifically, we first derive the regret upper bound for online learning, validating our motivation with a min-max optimization pattern. Based on this, we introduce two identical modules using Low-rank Adaptive (LoRA) with different optimization speeds to simulate intraspecific competition, and propose a new regularization term to guide their learning. To further mitigate catastrophic forgetting in cross-domain scenarios, we extend the OFS-DPO with LoRA modules combination strategy, resulting in the Cross domain Online Fast-Slow chasing DPO (COFS-DPO). This method leverages linear combinations of fast modules parameters from different task domains, fully utilizing historical information to achive continual value alignment. Experimental results show that OFS-DPO outperforms DPO in in-domain alignment, while COFS-DPO excels in cross-domain continual learning scenarios.