 Image credit: Original Paper
Image credit: Original PaperAbstract
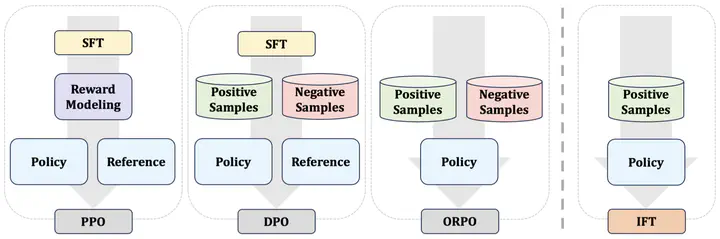
Supervised Fine-Tuning (SFT) and Preference Optimization (PO) are two fundamental processes for enhancing the capabilities of Language Models (LMs) post pre-training, aligning them better with human preferences. Although SFT advances in training efficiency, PO delivers better alignment, thus they are often combined. However, common practices simply apply them sequentially without integrating their optimization objectives, ignoring the opportunities to bridge their paradigm gap and take the strengths from both. To obtain a unified understanding, we interpret SFT and PO with two sub-processes – Preference Estimation and Transition Optimization – defined at token level within the Markov Decision Process (MDP) framework. This modeling shows that SFT is only a specialized case of PO with inferior estimation and optimization. PO evaluates the quality of model’s entire generated answer, whereas SFT only scores predicted tokens based on preceding tokens from target answers. Therefore, SFT overestimates the ability of model, leading to inferior optimization. Building on this view, we introduce Intuitive Fine-Tuning (IFT) to integrate SFT and Preference Optimization into a single process. IFT captures LMs’ intuitive sense of the entire answers through a temporal residual connection, but it solely relies on a single policy and the same volume of non-preference-labeled data as SFT. Our experiments show that IFT performs comparably or even superiorly to sequential recipes of SFT and some typical Preference Optimization methods across several tasks, particularly those requires generation, reasoning, and fact-following abilities. An explainable Frozen Lake game further validates the effectiveness of IFT for getting competitive policy.