News
People
Publications
Contact
English
English
中文 (简体)
Alignment
Intuitive Fine-Tuning: Towards Simplifying Alignment into a Single Process
Supervised Fine-Tuning (SFT) and Preference Optimization (PO) are two fundamental processes for enhancing the capabilities of Language …
Ermo Hua
,
Biqing Qi
,
Kaiyan Zhang
,
Yue Yu
,
Ning Ding
,
Xingtai Lv
,
Kai Tian
,
Bowen Zhou
PDF
Cite
Code
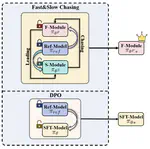
Online DPO: Online Direct Preference Optimization with Fast-Slow Chasing
Direct Preference Optimization (DPO) improves the alignment of large language models (LLMs) with human values by training directly on …
Biqing Qi
,
Pengfei Li
,
Fangyuan Li
,
Junqi Gao
,
Kaiyan Zhang
,
Bowen Zhou
PDF
Cite
Cite
×