 Image credit: Original Paper
Image credit: Original Paper摘要
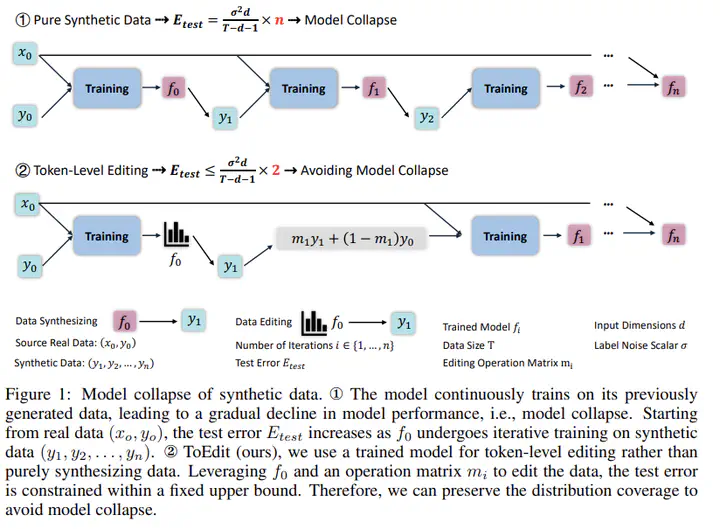
随着生成式人工智能的快速发展,合成数据在语言模型训练中的应用愈加广泛。然而,这也引发了一个关键问题——模型崩溃(Model Collapse),即模型在反复使用自身生成的数据进行训练时会出现性能持续下降的现象。本研究围绕两个核心问题展开:其一,合成数据对语言模型训练有何具体影响;其二,如何设计数据生成策略以有效避免模型崩溃。作者通过对不同合成比例的数据进行语言模型预训练,实证揭示了合成数据比例越高,模型性能越差的趋势,并进一步发现合成数据普遍存在分布覆盖不足和 n-gram 特征过度集中的问题。为此,研究提出了一种基于真实数据的 Token-Level 编辑策略(ToEdit),通过对模型高度确信的位置进行局部重采样,生成结构上更贴近真实分布的半合成数据。理论分析表明,该方法能够有效限制测试误差的上界,从而避免模型崩溃。在从零预训练、持续预训练与监督微调等多项实验中,该方法在不增加数据规模的前提下显著提升了模型在各类任务中的表现,验证了其理论可行性与实际有效性。
类型
出版物
ICML 2025