新闻动态
成员信息
科学研究
联系我们
中文 (简体)
中文 (简体)
English
Artificial Intelligence
When super-resolution meets camouflaged object detection: A comparison study.
Super-resolution (SR) and camouflage object detection (COD) are two prominent topics in the field of computer vision, with various …
Juan Wen
,
Shupeng Cheng
,
Peng Xu
,
Bowen Zhou
,
Weiyan Hou
,
Luc Van Gool
PDF
引用
代码
Fourier Position Embedding: Enhancing Attentions Periodic Extension for Length Generalization
通过改进旋转位置编码(Rotary Position Embedding,RoPE)来扩展语言模型(Language Models,LMs)的上下文长度已成为一种趋势。然而,现有的研究主要集中在解决 RoPE 在 Attention 中的局限性,而本文则对语言模型的几乎 …
Ermo Hua
,
Che Jiang
,
Xingtai Lv
,
Kaiyan Zhang
,
Ning Ding
,
Youbang Sun
,
Biqing Qi
,
Yuchen Fan
,
Xuekai Zhu
,
Bowen Zhou
PDF
引用
代码
Free Process Rewards without Process Labels
Different from its counterpart outcome reward models (ORMs), which evaluate the entire responses, a process reward model (PRM) scores a …
Lifan Yuan
,
Wendi Li
,
Huayu Chen
,
Ganqu Cui
,
Ning Ding
,
Kaiyan Zhang
,
Bowen Zhou
,
Zhiyuan Liu
,
Hao Peng
PDF
引用
代码
How to Synthesize Text Data without Model Collapse?
随着生成式人工智能的快速发展,合成数据在语言模型训练中的应用愈加广泛。然而,这也引发了一个关键问题——模型崩溃(Model Collapse),即模型在反复使用自身生成的数据进行训练时会出现性能持续下降的现象。本研究围绕两个核心问题展开:其一,合成数据对语言模型训练有何 …
Xuekai Zhu
,
Daixuan Cheng
,
Hengli Li
,
Kaiyan Zhang
,
Ermo Hua
,
Xingtai Lv
,
Ning Ding
,
Zhouhan Lin
,
Bowen Zhou
PDF
引用
MedXpertQA: Benchmarking Expert-Level Medical Reasoning and Understanding
我们提出了一个全面且具有高度挑战性的医学基准MedXpertQA,用于评估专家级的医学知识和高级推理能力。MedXpertQA 共包含 4,460 道题目,涵盖 17 个医学专科和 11 个身体系统。该基准包含两个子集:用于文本医学能力评估的 Text 子集,以及用于多 …
Yuxin Zuo
,
Shang Qu
,
Linhai Xie
,
Yifei Li
,
Zhangren Chen
,
Xuekai Zhu
,
Ermo Hua
,
Kaiyan Zhang
,
Ning Ding
,
Bowen Zhou
PDF
引用
代码
GenPRM: Scaling Test-Time Compute of Process Reward Models via Generative Reasoning
Recent advancements in Large Language Models (LLMs) have shown that it is promising to utilize Process Reward Models (PRMs) as …
Jian Zhao
,
Runze Liu
,
Kaiyan Zhang
,
Zhimu Zhou
,
Junqi Gao
,
Dong Li
,
Jiafei Lyu
,
Zhouyi Qian
,
Biqing Qi
,
Xiu Li
,
Bowen Zhou
PDF
引用
代码
A Survey of Efficient Reasoning for Large Reasoning Models: Language, Multimodality, and Beyond.
Recent Large Reasoning Models (LRMs), such as DeepSeek-R1 and OpenAI o1, have demonstrated strong performance gains by scaling up the …
Xiaoye Qu
,
Yafu Li
,
Zhaochen Su
,
Weigao Sun
,
Jianhao Yan
,
Dongrui Liu
,
Ganqu Cui
,
Daizong Liu
,
Shuxian Liang
,
Junxian He
,
Peng Li
,
Wei Wei
,
Jing Shao
,
Chaochao Lu
,
Yue Zhang
,
Xian-Sheng Hua
,
Bowen Zhou
,
Yu Cheng
PDF
引用
Technologies on Effectiveness and Efficiency: A Survey of State Spaces Models
State Space Models (SSMs) have emerged as a promising alternative to the popular transformer-based models and have been increasingly …
Xingtai Lv
,
Youbang Sun
,
Kaiyan Zhang
,
Shang Qu
,
Xuekai Zhu
,
Yuchen Fan
,
Yi Wu
,
Ermo Hua
,
Xinwei Long
,
Ning Ding
,
Bowen Zhou
PDF
引用
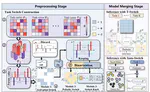
Less is More: Efficient Model Merging with Binary Task Switch
As an effective approach to equip models with multi-task capabilities without additional training, model merging has garnered …
Biqing Qi
,
Fangyuan Li
,
Zhen Wang
,
Junqi Gao
,
Dong Li
,
Peng Ye
,
Bowen Zhou
PDF
引用
代码
Can 1B LLM Surpass 405B LLM? Rethinking Compute-Optimal Test-Time Scaling
Test-Time Scaling (TTS) is an important method for improving the performance of Large Language Models (LLMs) by using additional …
Runze Liu
,
Junqi Gao
,
Jian Zhao
,
Kaiyan Zhang
,
Xiu Li
,
Biqing Qi
,
Wanli Ouyang
,
Bowen Zhou
PDF
引用
代码
»
引用
×