新闻动态
成员信息
科学研究
联系我们
中文 (简体)
中文 (简体)
English
Multi-Modal
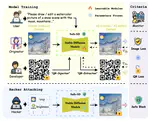
Safe-SD: Safe and Traceable Stable Diffusion with Text Prompt Trigger for Invisible Generative Watermarking
Recently, stable diffusion (SD) models have typically flourished in the field of image synthesis and personalized editing, with a range …
Zhiyuan Ma
,
Guoli Jia
,
Biqing Qi
,
Bowen Zhou
PDF
引用
Trust in Internal or External Knowledge? Generative Multi-Modal Entity Linking with Knowledge Retriever
Multi-modal entity linking (MEL) is a challenging task that requires accurate prediction of entities within extensive search spaces, …
Xinwei Long
,
Jiali Zeng
,
Fandong Meng
,
Jie Zhou
,
Bowen Zhou
引用
AdapEdit: Spatio-Temporal Guided Adaptive Editing Algorithm for Text-Based Continuity-Sensitive Image Editing
With the great success of text-conditioned diffusion models in creative text-to-image generation, various text-driven image editing …
Zhiyuan Ma
,
Guoli Jia
,
Bowen Zhou
PDF
引用
代码
Generative Multi-Modal Knowledge Retrieval with Large Language Models
Knowledge retrieval with multi-modal queries plays a crucial role in supporting knowledge-intensive multi-modal applications. However, …
Xinwei Long
,
Jiali Zeng
,
Fandong Meng
,
Zhiyuan Ma
,
Kaiyan Zhang
,
Bowen Zhou
,
Jie Zhou
PDF
引用
引用
×